News Story
Clark School Researchers Help Decode Speech Recognition
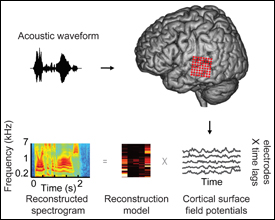
Participants listened to words (acoustic waveform, top left), while neural signals were recorded from cortical surface electrode arrays (top right, red circles) implanted over superior and middle temporal gyrus (STG, MTG). Speech-induced cortical field potentials (bottom right, gray curves) recorded at multiple electrode sites were used to fit multi-input, multi-output models for offline decoding. The models take as input time-varying neural signals at multiple electrodes and output a spectrogram consisting of time-varying spectral power across a range of acoustic frequencies (180–7,000 Hz, bottom left). To assess decoding accuracy, the reconstructed spectrogram is compared to the spectrogram of the original acoustic waveform. Photo courtesy PLoS Biology.
Clark School Professor Shihab Shamma (electrical and computer engineering/Institute for Systems Research [ISR]), former ISR postdoctoral researcher Stephen David*, and alumnus Nima Mesgarani** (Ph.D. '08, electrical engineering) are three of the authors of a new study on how the human auditory system processes speech, published in the Jan. 31, 2012, edition of PLoS Biology.
”Reconstructing Speech from Human Auditory Cortex” details recent progress made in understanding the human brain's computational mechanisms for decoding speech. The researchers took advantage of rare neurosurgical procedures for the treatment of epilepsy, in which neural activity is measured directly from the brain’s cortical surface—a unique opportunity for characterizing how the human brain performs speech recognition. The recordings helped researchers understand what speech sounds could be reconstructed, or decoded, from higher order brain areas in the human auditory system.
The decoded speech representations allowed readout and identification of individual words directly from brain activity during single trial sound presentations. The results provide insights into higher order neural speech processing and suggest it may be possible to readout intended speech directly from brain activity. Potential applications include devices for those who have lost the ability to speak through illness or injury.
Brian N. Pasley, Helen Wills Neuroscience Institute, University of California Berkeley is the paper’s lead author. In addition to the Clark School-affiliated co-authors, additional co-authors include Robert Knight, University of California San Francisco and University of California Berkeley; Adeen Flinker, University of California Berkeley; Edward Chang, University of California San Francisco; and Nathan Crone, Johns Hopkins University.
* Stephen David is now an assistant professor at Oregon Health & Science University, where he heads the Laboratory of Brain, Hearing, and Behavior in the Oregon Hearing Research Center.
** Nima Mesgarani is currently a postdoctoral researcher in the Neurological Surgery Department of the University of California, San Francisco School of Medicine.
| Read a story about this research in USA Today |
Published February 6, 2012
Related Stories
Stories / January 17, 2019
Radio interview with Jonathan Simon on "the cocktail party...

Stories / February 1, 2010
Auditory Cortex Study Reveals Cells' "Individuality"

Stories / Jul 24, 2026
Securing Edge Devices for the Post-Quantum Era

Stories / Jul 24, 2026
University System of Maryland and NASA Sign Five-Year Space Act...

Stories / Jul 23, 2026
New Graduate Program Teaches Real-World Autonomy Skills

Stories / Jul 22, 2026
Hartzell Named to 40 under 40 by Georgia Tech Alumni

Stories / Jul 20, 2026
Ríos Ocampo Awarded NSF CAREER to Advance New Class of...

Stories / Jul 20, 2026
Building Bridges to Accelerate Innovation

Stories / Jul 15, 2026
New Tool Reveals Hidden Security Risks in AI Systems

Stories / Jul 14, 2026
High-Impact Studies Advance Next-Generation Batteries Through...

Stories / Jul 13, 2026
Meet the Newest Cohort of the MARC Program

Stories / Jul 13, 2026
University of Maryland Named Top Contributing Institution in...
